
Thoughts on reCAPTCHA v3
Google’s new reCAPTCHA comes with new questions.
Google has been a big player in the CAPTCHA space for the better part of 2 decades and their latest version has turned the product in a new direction, one that provides the user more power but little guidance on how to wield it.
Disclaimer: I work at Shape Security where I built a paid product that aims to do what Google’s free reCAPTCHA service couldn’t. I’m certainly biased and my experience and comments in this space should be taken with a grain of salt.
A quick reCAPTCHA reCap
CAPTCHAS, short for Completely Automated Public Turing test to tell Computers and Humans Apart, are challenges that are used to block robots and let humans in. You commonly see these on website forms where they are used to block repeated, automated submissions. Automating web requests is a common tactic for unsavory actors who need to perform simple actions millions and millions of times in order for their effort to be worthwhile. An example of this is automated comment spam, something like a veiled advertisement that links to some sketchy pharmacy in Russia. A single spam message like that in just one forum on the web is unlikely to generate many hits for the spammer. On the other hand, millions and millions of messages across thousands of websites greatly increases the chances someone will not only click on the link but end up buying whatever is advertised. CAPTCHAs are designed to block the ability for spammers and criminals to scale their digital enterprises.

Google’s original maroon and cream reCAPTCHA is a nostalgic reminder of the web 2.0 era of internet applications. 2 squiggly words stood in your way at almost every corner of the internet and millions of hours of human effort was spent deciphering them. It wasn’t that much different than earlier CAPTCHAs but Google reapplied the idea to help them transcribe books and other literature that existed on actual, real world paper. One word was the human test and the other was a word that needed human assistance to process. Good, human users would then end up feeding data back into Google’s system making it smarter over time. As a CAPTCHA, it probably worked for a little bit but criminals ended up bypassing it relatively quickly and it became a low hurdle for entry in the automation game. Because it was so easily bypassed (so easy that marketplaces formed around solving it) it ended up mostly just annoying real users without providing much benefit to the implementers.
In order to manage the user experience problem, reCAPTCHA was revamped in v2, the former state-of-the-art offering up until late October 2018. The experience was dramatically better, there was virtually no work a user had to do besides click a box on the screen. This removed a lot of the friction in user flows that were very sensitive to it, but how did it do against fighting bots?

If you weren’t able to automatically get that green checkmark then it meant that Google didn’t have enough data to positively assess your legitimacy and you were then prompted with a modernized CAPTCHA challenge. This came in the form of a puzzle-like grid where you selected the parts of a picture that matched road signs, cars, roads, crosswalks, etc. If you’re following along you can probably already assume where this data was going. All this data, just like in v1, was fed back into Google’s computer vision systems in order to improve the ability to automatically extract information from the physical world.
Introducing reCAPTCHA v3
The third incarnation of Google’s reCAPTCHA was recently released and has no fallback challenge and no user interface — it is completely invisible. This is as good as it gets from the user experience perspective but they’ve also changed how implementers are expected to interact with the tool. Instead of taking care of the decision on Google’s side, version 3 now provides a score between 0.0 and 1.0 back to the customer which is Google’s assessment on how “botlike” this traffic is. This flips the responsibility of what to do with that assessment onto the customer along with how to identify and manage false positives and false negatives. False positives (humans that were incorrectly blocked) used to have a “second chance” to prove themselves human via the fallback challenge, ensuring good traffic could still get in even if they tripped over the initial check. False negatives (bots that weren’t caught), presumably, were addressed by Google’s services getting better over time.
From defeating bots to analyzing risk
The major difference between the earlier versions and this latest version is that Google is now no longer claiming that it is differentiating between human and non-human traffic, it is delivering a risk score and the consumer now needs to figure out what to do with it.
It’s too early to know the implications of this reversal of responsibility as an average web user. If you score low now, what can you do? How long might you be locked out of a service because your reputation fell? Do you call customer service? Google’s transparency is going to be tested here.
How likely is it that a legitimate user might score low enough to be blocked anyway? Google recommends starting at a 0.5 and moving from there. Is that good enough?
Two of the data points that we know Google looks at when assessing legitimacy is your IP and ASN reputation (an ASN is, effectively, an identifier for the service provider you are using). I spun up a quick instance of Amazon Workspaces, a useful remote desktop solution that runs on Amazon’s cloud, and tested my score against Firefox and Chrome. I used Amazon because it is, typically, not a consumer ASN and consumer-website traffic typically does not originate from Amazon’s servers. Amazon workspaces, though, is a legitimate way of using sandboxed operating systems from a variety of devices and represents a good example of why this reCAPTCHA is fundamentally different than the previous.
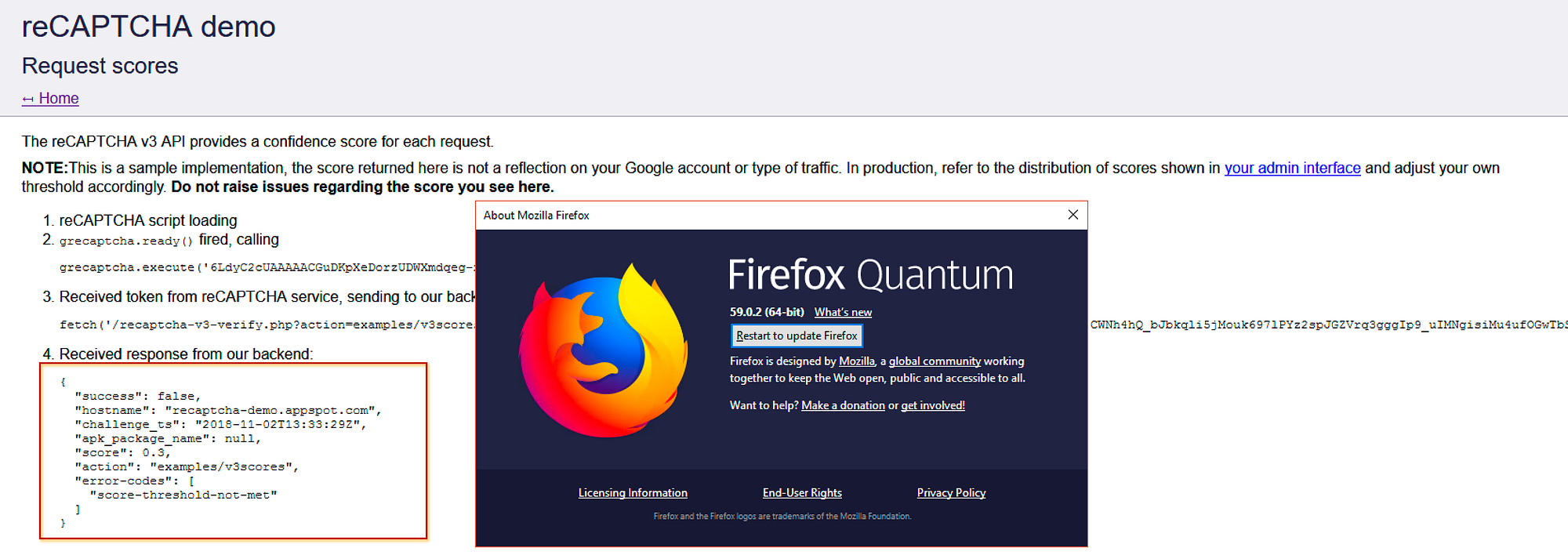
Both Chrome and Firefox scored a 0.3 which is low enough to be blocked by default despite being run manually by a human being. In comparison, reCAPTCHA v2 presented me with the fallback challenge which, when completed, returned a successful result for me. This is the core difference that will now need to be managed by each consumer of new reCAPTCHA service — when you are presented with a low score, what do you do with that request? Previously, Google managed the challenge but now there is no clear solution.
On the opposite end, my home machine running the latest Chrome nets me a score of 0.9 which is on the extreme high end of trustability. Strangely, though, when automating a headless Chrome instance via node.js and the devtools protocol I got a score of 0.7 on reCAPTCHA v3 but on reCAPTCHA v2 I am faced with the fallback challenge. This means that my automated browser passed by v3 without an issue but is effectively blocked by v2. This is likely because Google has enough data on my environment and IP to assume that traffic coming from this machine is less likely to be malicious than the Amazon traffic.
Relying on AI alone isn’t suitable
Any analysis of an anti-automation solution requires far more than a handful of requests to come to a conclusion on longterm efficacy, especially one so heavily built on Google’s legendary machine learning systems. It is easy to craft a request that fits a desired narrative. The examples above are not meant to point out flaws in reCAPTCHA’s ability to detect bots vs humans, they are meant to point out that any system will have fuzzy boundaries where false positives and negatives are inherently more probable. Google just doesn’t yet have good answers for what you are supposed to do in those cases.
The new reCAPTCHA score just becomes one more data point that an internal team needs to manage in order to stay on top of their traffic. This may be better overall but is a departure from the one-stop-shop reCAPTCHA Google has been delivering over the years and the current documentation doesn’t sufficiently detail the implications of moving to v3. The docs do acknowledge that v3 is more suitable for situations where showing a challenge is not desired and claims that v2 will not be going away. Given the changes and the coexistence with v2, v3 seems like a new product line rather than a version bump and we’ll have to see where it goes from here.
This new version of reCAPTCHA is a welcome change, despite any concerns. Assessing malicious traffic is a very complicated problem and previous CAPTCHA attempts only provided a weak security blanket that ineffectively masked the complexity for years. Using the new reCAPTCHA will be some work and will take some rearchitecting of applications but that’s probably necessary at this point regardless. It’s helpful to see one of the biggest players in the game start to turn the messaging around even if there is room for improvement.
Thanks for reading! If you use v3 in production, please reach out to me with your experiences — you can catch me on twitter at @jsoverson or via email.
